
はじめに
クラスター分析は、データの中から似た特徴を持つグループ(クラスター)を見つけ出す教師なし学習の手法です。マーケティング分野では、顧客の属性や購買行動をもとにセグメンテーションを行い、ターゲットに合わせた戦略策定に役立てられています。
この記事では、基本概念の解説に加え、具体的な実装例とその応用事例を詳しく紹介します。
クラスター分析の理論と手法の比較
クラスター分析は、データ内の自然なグループを発見するための方法です。代表的な手法として、以下の2種類が挙げられます。
- 階層型クラスタリング
- 特徴: デンドログラム(樹形図)を利用して、データ間の階層的な関係を可視化します。
- メリット: 小規模データ向けに適しており、グループ間の関係性が直感的に理解できます。
- デメリット: データ量が多い場合、計算負荷が大きくなりがちです。
- k-means法
- 特徴: 指定した数のクラスタにデータを分割する方法。
- メリット: 計算効率が良く、大規模データにも適用可能。
- デメリット: 初期値に依存しやすく、事前にクラスタ数を設定する必要があります。
k-meansを用いた実装例とその解説
以下は、アヤメ(Iris)データセットを使って、k-means法により3つのクラスタに分類する実装例です。
サンプル1:シンプルな可視化
!pip install japanize-matplotlib
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn import datasets
# Irisデータセットの読み込み
iris = datasets.load_iris()
# k-meansクラスタリングの実施
kmeans = KMeans(n_clusters=3, random_state=42)
clusters = kmeans.fit_predict(iris.data)
# 結果の可視化:最初の2つの特徴量を利用
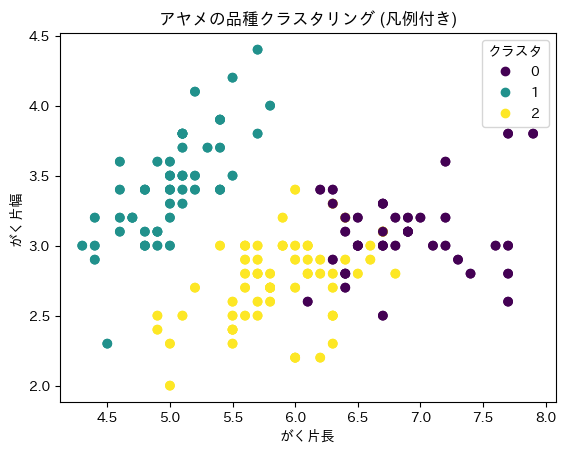
plt.scatter(iris.data[:,0], iris.data[:,1], c=clusters, cmap='viridis')
# 凡例を追加
scatter = plt.scatter(iris.data[:,0], iris.data[:,1], c=clusters, cmap='viridis')
plt.legend(*scatter.legend_elements(), title="クラスタ")
plt.xlabel('がく片長')
plt.ylabel('がく片幅')
plt.title('アヤメの品種クラスタリング (凡例付き)')
plt.show()
サンプル2:クラスターの中心を追加
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn import datasets
# Irisデータセットの読み込み
iris = datasets.load_iris()
# k-meansクラスタリングの実施
kmeans = KMeans(n_clusters=3, random_state=42)
clusters = kmeans.fit_predict(iris.data)
# 結果の可視化:最初の2つの特徴量を利用
plt.scatter(iris.data[:,0], iris.data[:,1], c=clusters, cmap='viridis')
# クラスタ中心をプロット
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', marker='x', s=200, label='クラスタ中心')
# 凡例を追加
scatter = plt.scatter(iris.data[:,0], iris.data[:,1], c=clusters, cmap='viridis')
plt.legend(*scatter.legend_elements(), title="クラスタ")
plt.legend(loc='upper left')
plt.xlabel('がく片長')
plt.ylabel('がく片幅')
plt.title('アヤメの品種クラスタリング (クラスタ中心と凡例付き)')
plt.show()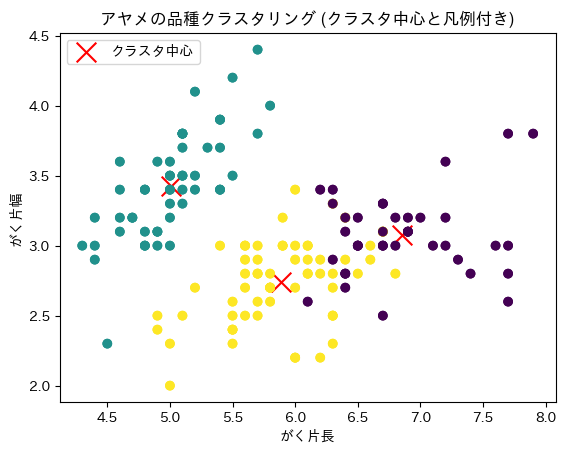
ビジネスでの具体的な応用例
- 顧客セグメンテーション:
顧客の購買履歴や属性データをもとに、似た特徴を持つグループに分類し、それぞれに最適なマーケティング戦略を実施。 - 店舗立地分析:
地域ごとの購買パターンや人口統計データを分析し、最適な出店エリアを決定。 - ウェブサイト行動解析:
訪問者のアクセスログや行動パターンをクラスタリングし、サイト改善やパーソナライズ戦略に反映。
まとめ
クラスター分析は、データ内の隠れたパターンやグループを抽出するための有力な手法です。理論背景や各手法の特性を理解した上で、実際のデータに適用することで、ビジネスの意思決定やマーケティング戦略に大きなインサイトをもたらします。まずは基本的な実装例から学び、さまざまな手法のメリット・デメリットを比較しながら応用していくと良いでしょう。

