はじめに
人工知能(AI)技術の一種である「強化学習」について、初心者の方にもわかりやすく解説します。強化学習の基本概念から実際の応用例まで、体系的に学べる内容となっています。
強化学習とは?
強化学習(Reinforcement Learning)とは、機械学習の一分野で、環境との相互作用を通じて試行錯誤しながら「価値を最大化するような行動」を学習するアプローチです。人間や動物が経験から学ぶ過程に着想を得た学習方法といえます。
強化学習では、エージェント(学習する主体)が環境の中で行動し、その結果として得られる報酬を基に、より良い行動を学んでいきます。例えば、ゲームをプレイするAIは、勝つための戦略を試行錯誤しながら学習していくのです。
「教師あり学習」が正解データから学ぶのに対し、強化学習は「試行錯誤から得られる報酬」を手がかりに学習するため、より人間の学習プロセスに近いと言われています。
他の機械学習手法との違い
機械学習は主に以下の3つのカテゴリーに分類されます:
| 学習タイプ | 特徴 | 例 |
|---|---|---|
| 教師あり学習 | 正解ラベルを持つデータから学習 | 画像分類、スパムメール検出 |
| 教師なし学習 | ラベルなしデータからパターンを発見 | クラスタリング、次元削減 |
| 強化学習 | 報酬を最大化する行動を学習 | ゲームAI、ロボット制御 |
強化学習の最大の特徴は、明示的な正解データなしで学習できる点です。代わりに、「行動の結果としての報酬」を基に学習を進めます。このプロセスは人間が新しいスキルを身につける過程に似ています。
具体例で理解する違い
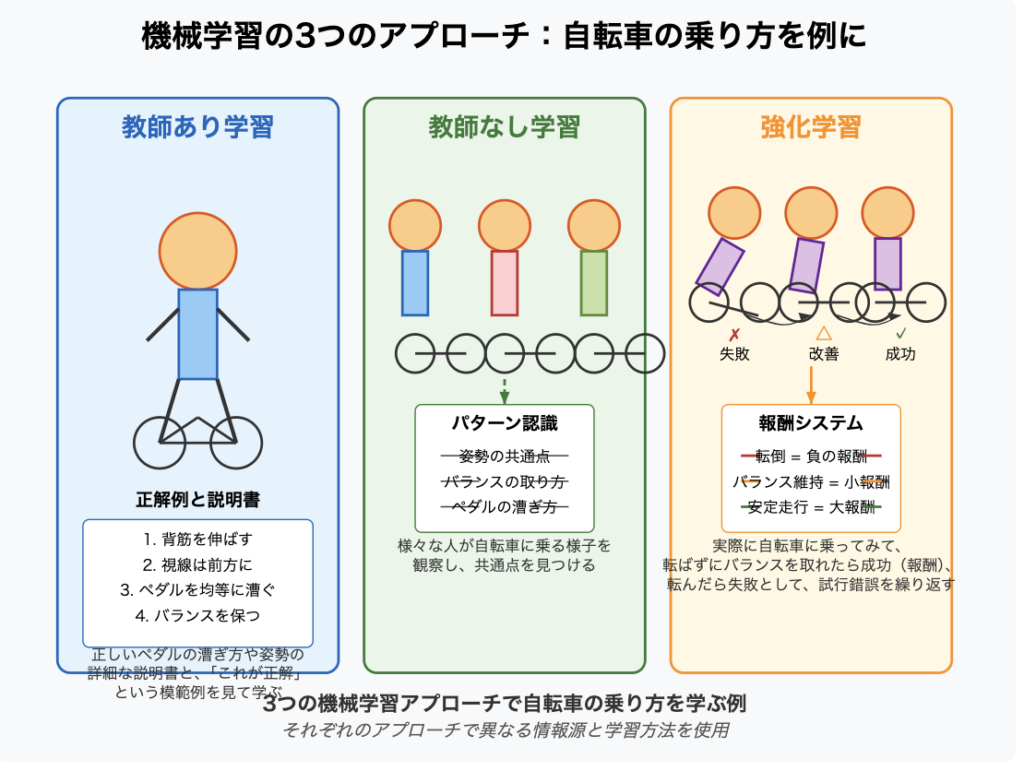
自転車の乗り方を学ぶ場合:
- 教師あり学習:正しいペダルの漕ぎ方や姿勢の詳細な説明書と、「これが正解」という模範例を見て学ぶ
- 教師なし学習:様々な人が自転車に乗る様子を観察し、共通点を見つける
- 強化学習:実際に自転車に乗ってみて、転ばずにバランスを取れたら成功(報酬)、転んだら失敗として、試行錯誤を繰り返す
強化学習の基本概念
強化学習を理解するためには、いくつかの重要な概念を把握する必要があります。
基本要素
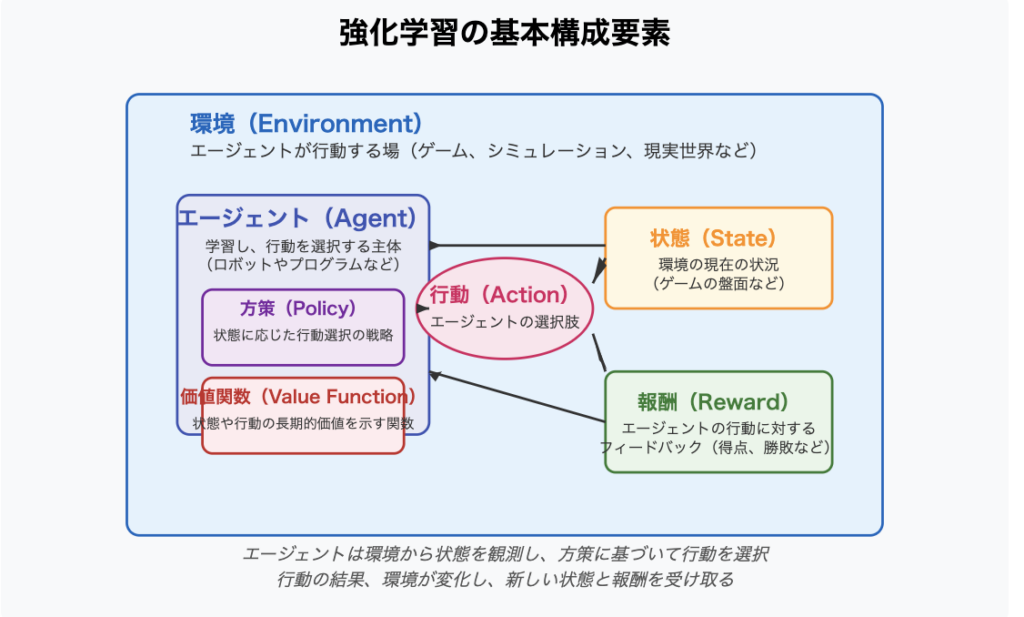
- エージェント(Agent):学習し、行動を選択する主体(ロボットやプログラムなど)
- 環境(Environment):エージェントが行動する場(ゲーム、シミュレーション、現実世界など)
- 状態(State):環境の現在の状況(ゲームの盤面など)
- 行動(Action):エージェントが選択できる選択肢
- 報酬(Reward):エージェントの行動に対するフィードバック(得点、勝敗など)
- 方策(Policy):状態に応じてどのような行動を取るかの戦略
- 価値関数(Value Function):長期的に見て、ある状態や行動がどれだけ価値があるかを示す関数
強化学習の基本サイクル
この繰り返しのプロセスにより、エージェントは徐々に良い行動を学んでいきます。
強化学習の仕組み
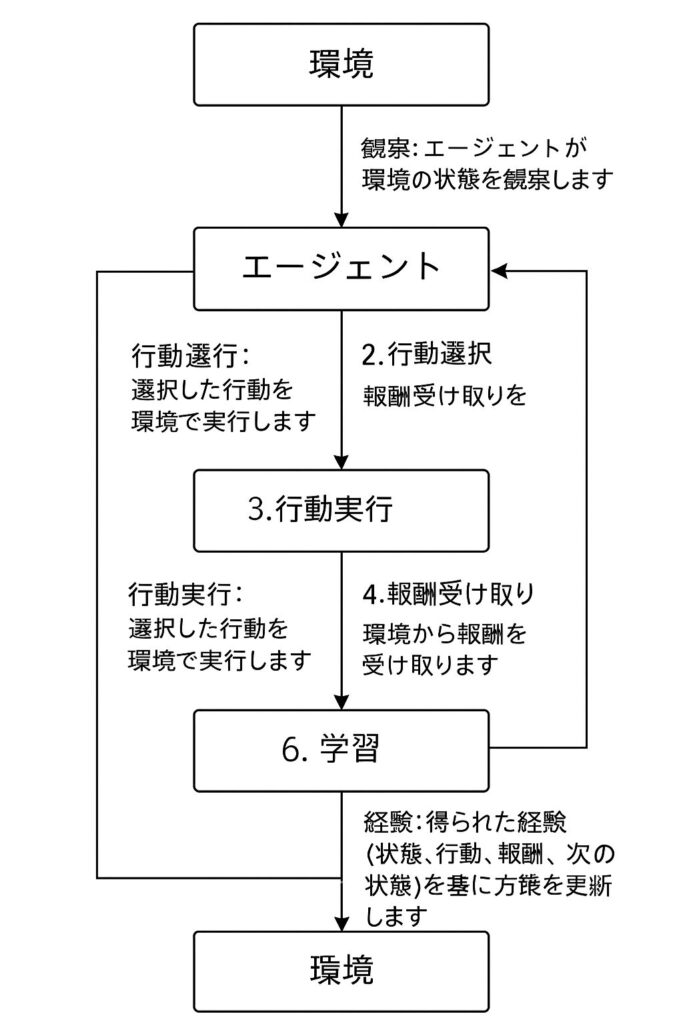
強化学習では、以下のステップを繰り返すことで学習を進めていきます:
- 観察:エージェントが環境の状態を観察します
- 行動選択:現在の状態に基づいて行動を選択します
- 行動実行:選択した行動を環境で実行します
- 報酬受け取り:環境から報酬を受け取ります
- 状態遷移:環境が新しい状態に変化します
- 学習:得られた経験(状態、行動、報酬、次の状態)を基に方策を更新します
重要ポイント:短期的な報酬と長期的な報酬のバランス
強化学習では、即時的な報酬だけでなく、将来にわたる報酬の総和を最大化することが目標です。 これは「即時報酬」と「将来の報酬の期待値」のバランスを取る必要があります。
例えば、テトリスで1行だけすぐに消すよりも、4行同時に消した方が高得点になるため、 短期的には不利な行動(ブロックを積み上げる)を選ぶことで、長期的には高い報酬を得られる場合があります。
探索と活用のジレンマ
強化学習における重要な課題の一つが「探索(Exploration)と活用(Exploitation)のバランス」です。
- 探索:新しい行動を試してみること(未知の可能性を探る)
- 活用:これまでの経験から最も良いと思われる行動を選ぶこと(既知の最良を活用)
このバランスを適切に取ることが、効率的な学習のために重要です。初期段階では探索を多く行い、学習が進むにつれて活用に重点を置く「イプシロン・グリーディ法」などの手法がよく使われます。
主要なアルゴリズム
強化学習には様々なアルゴリズムがありますが、初心者が理解すべき主要なものを紹介します。
Q学習(Q-Learning)
Q学習は最も基本的な強化学習アルゴリズムの一つです。特定の状態で特定の行動を取ることの価値を「Q値」として学習します。
Q学習の基本的な考え方:
各状態と行動のペアに対して「Q値」を持ち、行動の結果に基づいてこの値を更新していきます。 ある状態では、Q値が最も高い行動を選択することで、最適な行動を取れるようになります。
更新式:
Q(s,a) ← Q(s,a) + α[r + γ・max<sub>a'</sub>Q(s',a') - Q(s,a)]
ここで、αは学習率、γは割引率、rは報酬、s’は次の状態を表します。
SARSA(State-Action-Reward-State-Action)
SARSAはQ学習と似ていますが、価値の更新方法が異なります。次の状態で「実際に選択する」行動の価値を用いて更新します。
更新式:
Q(s,a) ← Q(s,a) + α[r + γ・Q(s',a') - Q(s,a)]
Q学習が「max」を使うのに対し、SARSAは実際に選択する次の行動a’のQ値を使います。 これにより、SARSAはより「安全志向」の傾向があります。
モンテカルロ法
モンテカルロ法は、一連のエピソード(初期状態から終了状態までの一連の流れ)を完了した後に学習を行います。
モンテカルロ法の特徴:
- エピソードが完了するまで待って、その後に価値を更新
- 実際に得られた報酬の総和に基づいて学習
- 環境のモデルを必要としない
Q学習やSARSAがステップごとに更新するのに対し、モンテカルロ法はエピソード終了後にまとめて更新します。
アルゴリズムの選択基準
各アルゴリズムには長所と短所があり、問題の性質によって適切なものが変わります:
- Q学習:最も汎用的で、多くの状況で使える
- SARSA:リスクを回避する必要がある場合に有効
- モンテカルロ法:エピソードが明確に区切られる問題や、長期的な報酬が重要な場合に有効
深層強化学習とは
深層強化学習(Deep Reinforcement Learning)は、強化学習とディープラーニング(深層学習)を組み合わせたアプローチです。これにより、従来の強化学習では扱いきれなかった複雑な問題にも対応できるようになりました。
なぜ深層強化学習が必要なのか?
従来の強化学習では、状態と行動の組み合わせが増えると(例:チェスや囲碁のような複雑なゲーム)、すべての組み合わせに対してQ値を持つことが現実的ではなくなります。これを「状態空間の爆発」問題と呼びます。
深層強化学習では、ニューラルネットワークを使って状態から価値や行動を推定することで、この問題を解決します。
代表的な深層強化学習アルゴリズム
- DQN(Deep Q-Network):Q学習にディープラーニングを組み合わせたもの
- A3C(Asynchronous Advantage Actor-Critic):複数のエージェントを並列に学習させる手法
- PPO(Proximal Policy Optimization):方策勾配法の一種で、安定した学習が特徴
深層強化学習の成功例
2016年、GoogleのDeepMind社が開発した「AlphaGo」が世界トップクラスの囲碁棋士に勝利したことは、 深層強化学習の可能性を世界に示した象徴的な出来事でした。 AlphaGoは、深層学習と強化学習を組み合わせることで、人間が数千年かけて蓄積してきた知識を超える能力を獲得しました。
強化学習の応用例
強化学習は様々な分野で応用が進んでいます。以下に代表的な例を紹介します。
ゲームAI
- AlphaGo/AlphaZero:囲碁、チェス、将棋などのボードゲームで人間を超える性能を実現
- Atariゲーム:ブロック崩しやスペースインベーダーなどの古典的ゲームでも人間レベルのプレイが可能に
- StarCraft II:複雑な戦略ゲームでもプロレベルの戦術を学習
ロボティクス
- 歩行ロボット:様々な地形での安定した歩行を学習
- ロボットアーム:物体の把持や細かい作業の実行
- ドローン制御:複雑な飛行パターンや障害物回避
自動運転
- 複雑な交通状況での判断
- 安全な運転戦略の学習
- 自動駐車技術
エネルギー最適化
- データセンターの冷却システム制御
- スマートグリッドでの電力配分最適化
- 再生可能エネルギーの活用最適化
金融・トレーディング
- 株式トレーディング戦略の最適化
- リスク管理
- ポートフォリオ管理
推薦システム
- 動画配信サービスの推薦(Netflix、YouTubeなど)
- 広告表示の最適化
- ECサイトでの商品推薦
事例:エレベーター制御システム
高層ビルのエレベーター制御にも強化学習が応用されています。乗客の待ち時間最小化という「報酬」を最大化するよう、 時間帯や曜日ごとの利用パターンを学習し、最適なエレベーター配置を実現します。 数理的な手法だけでは対応しきれない複雑なパターンにも対応できるため、 タワーマンションやオフィスビルなどで活用されています。
強化学習の未来と展望
強化学習は急速に発展している分野であり、今後も様々な進化が期待されています。
現在の課題
- サンプル効率:大量の試行が必要で学習に時間がかかる
- 探索の難しさ:報酬が稀な環境での効率的な探索
- 安全性と倫理:実世界での応用における安全な探索
- 転移学習:一つの環境で学んだことを別の環境に応用する難しさ
今後の展望
- より効率的な学習アルゴリズム:少ないサンプル数でも学習できる手法の開発
- マルチタスク学習:複数のタスクを同時に学習できる汎用的なエージェントの開発
- 人間との協調:人間のフィードバックを取り入れた学習の発展
- 実世界での応用拡大:医療、製造業、農業などへの応用拡大
強化学習は、人工知能が「自ら学ぶ能力」を獲得するための重要な技術です。 将来的には、より人間に近い形で学習し、複雑な問題を解決できるAIの開発につながるでしょう。
まとめ
強化学習は、環境との相互作用を通じて試行錯誤しながら学習するという、人間の学習過程に近い手法です。 基本的には「状態を観察」→「行動を選択」→「報酬を受け取る」→「方策を更新する」というサイクルを繰り返すことで学習が進みます。
主要なアルゴリズムとしては、Q学習、SARSA、モンテカルロ法などがあり、 深層学習と組み合わせた深層強化学習によって、より複雑な問題にも対応できるようになりました。
強化学習の応用範囲は、ゲームAIから自動運転、ロボット制御、金融トレーディング、推薦システムまで多岐にわたります。 課題も多く残されていますが、今後の技術発展により、さらに幅広い分野での活用が期待されています。
初心者が強化学習を学ぶためのステップ
- 機械学習の基礎知識を身につける
- Python言語の基本を習得する
- Q学習などの基本的なアルゴリズムを理解する
- OpenAI Gymなどのシミュレーション環境で実験してみる
- 徐々に複雑な問題に挑戦する
強化学習は直感的に理解しやすい面もありますが、実装は複雑になりがちです。 焦らず段階的に学んでいくことをおすすめします。
